Why Score Is Not Stable
Each Zold node has a score that reflects the amount of CPU power it managed to invest into the system. It is expected that the longer the node is online, the larger the score. However, this is not the case, because the score expires in 24 hours and has to be re-calculated again. Here is a quick summary of how exactly score farming works.
According to the White Paper, in order to earn a score, a node has to create a prefix and then find a number of text suffixes, which will satisfy a simple condition: a concatenation of them with the prefix has to produce a zero-ending text after being passed through SHA-256 hash-generating algorithm. The prefix, according to our requirements, has to include the ISO-8601 time of the moment it was created, for example:
2018-06-27T06:22:41Z b2.zold.io 4096 THdonv1E@abcdabcdabcdabcdHere, 2018-06-27T06:22:41Z is the time when this prefix has been created. Here is the
first suffix a node may find: 3a934b. Here is how
the entire text will look, before being sent to the SHA-256 hashing:
2018-06-27T06:22:41Z b2.zold.io 4096 THdonv1E@abcdabcdabcdabcd 3a934bThe hash of this string will look like this:
c9c72efbf6beeea13408c5e720ec42aec017c11c3db335e05595c03755000000Pay attention to the trailing zeroes. There are six of them. This is the strength of the score. It’s six. And the value of the score is one, because only one suffix was found and attached. The more suffixes are there, the bigger the value, the more valuable is the voice of this particular node among all others. This is how the proof-of-work works in Zold.
This is how the value of the score may look when growing in time:
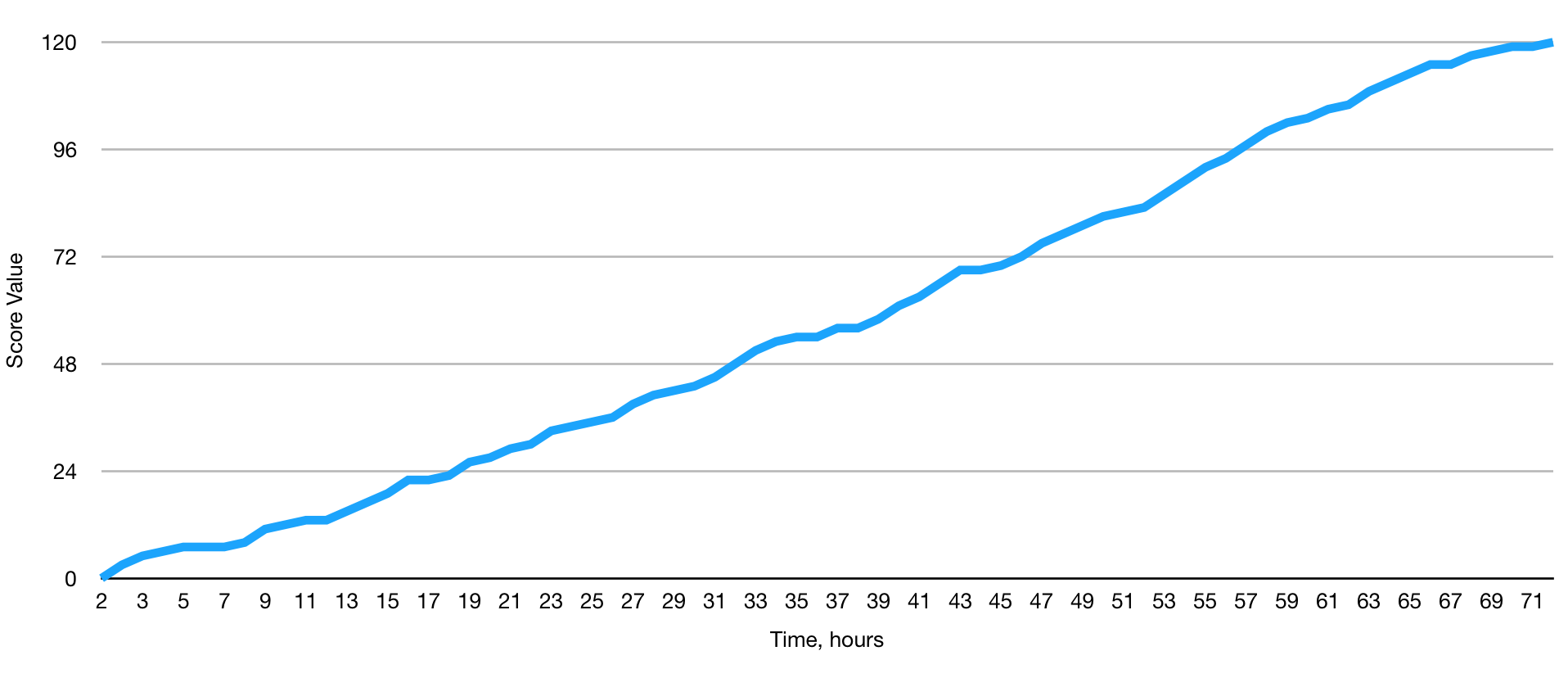
However, a node cannot keep finding those suffixes, endlessly growing the value of the score. At some point it has to stop. This will happen exactly in 24 hours after the moment the prefix was created. The score you see above expired a long time ago. If your node shows it to others, they will reject it and the voice of your node won’t be taken into account. The score has to be fresh enough in order to matter.
Here comes the problem I wanted to explain. If the node keeps working on those suffixes, trying to find them, for 24 hours, its score will grow to a big number. However, in 24 hours it will be wasted and the node will have to start again. This is how the graph will look in reality:
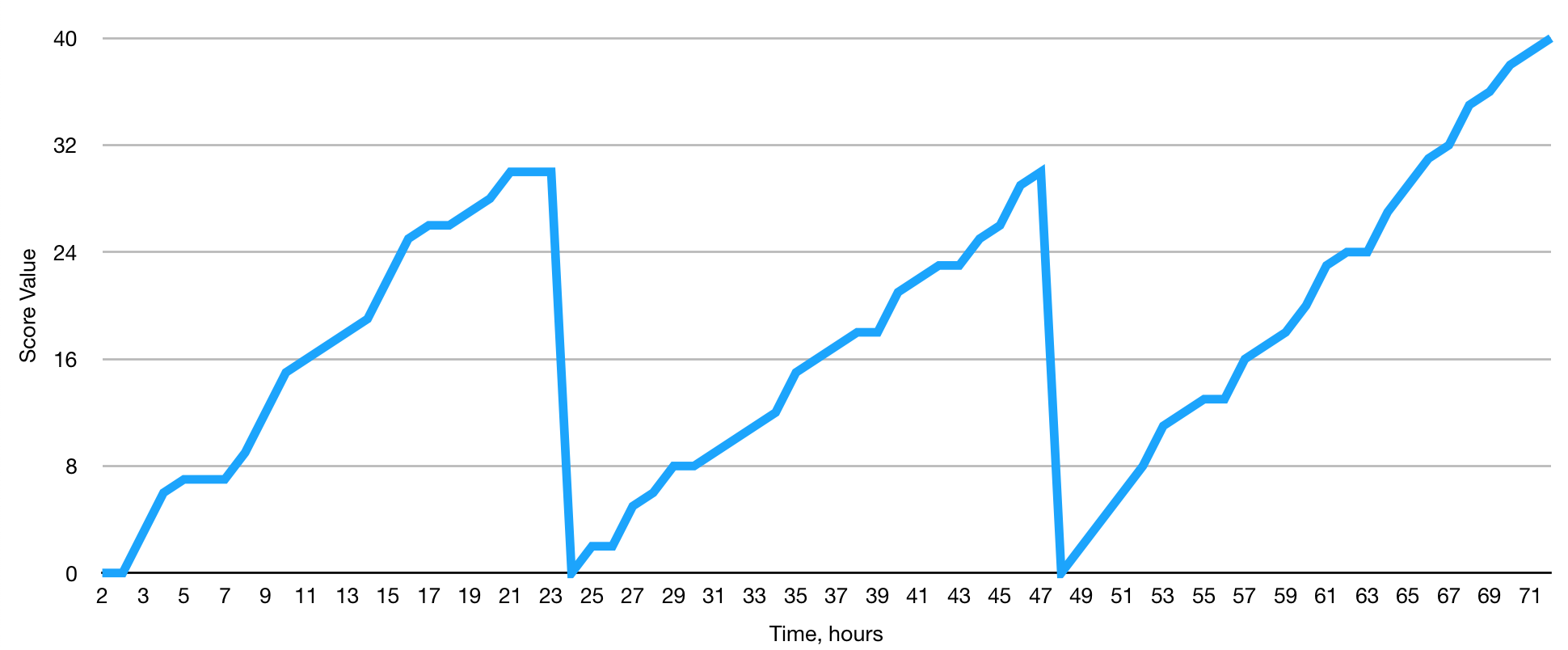
Thus, the node will lose its voting power every 24 hours. It will stop receiving taxes and hosting bonuses. This is not what node owners really want. In order to solve this issue we calculate a number of scores at the same time, in parallel processes. But if we just calculate them in parallel, the graph will look like this:
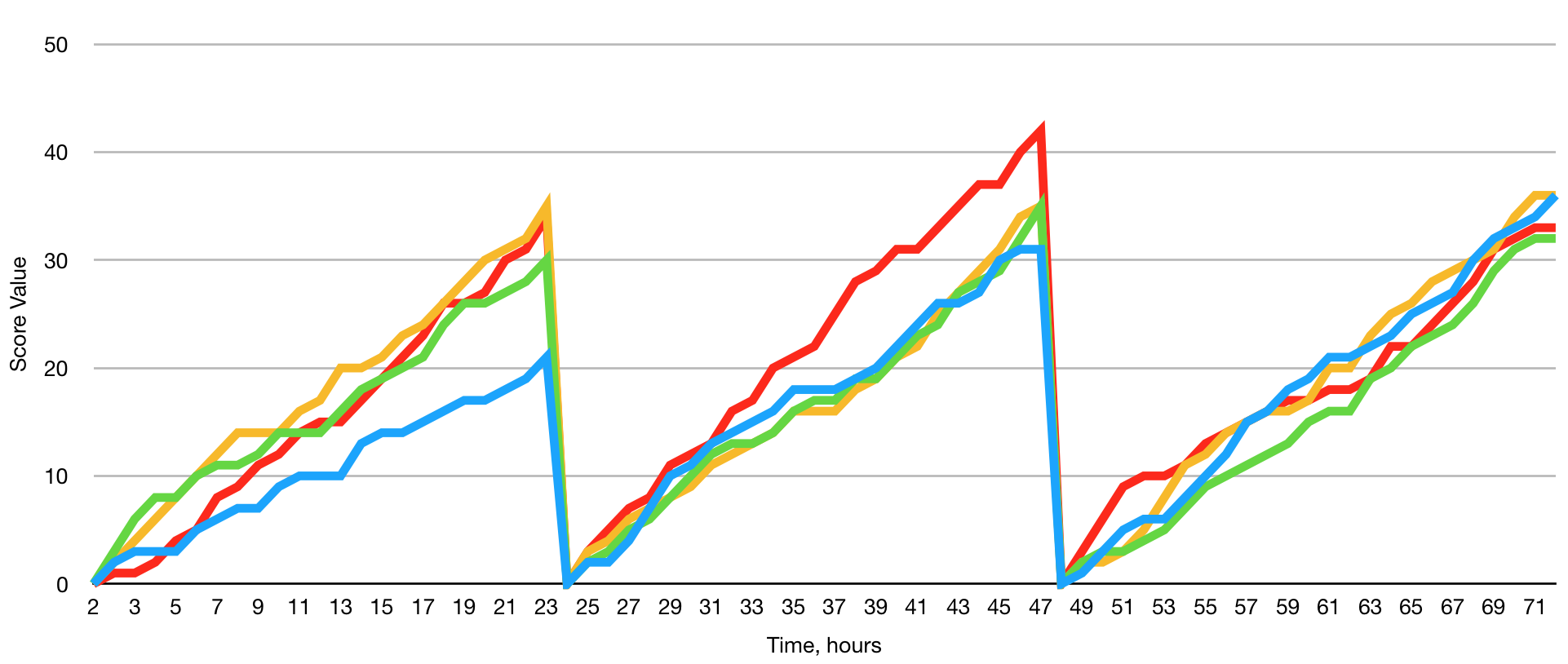
They will grow and expire synchronously. The result will not differ much from what we had with a single process.
The solution, however, is simple, we start calculating new scores a few times per day. And the distance between starting points depends on the number of “threads” (parallel processes) the node has configured. If the node runs 4 parallel threads, we start a new score every 6 hours (24 divided by 4). Here is how the graph will look like:
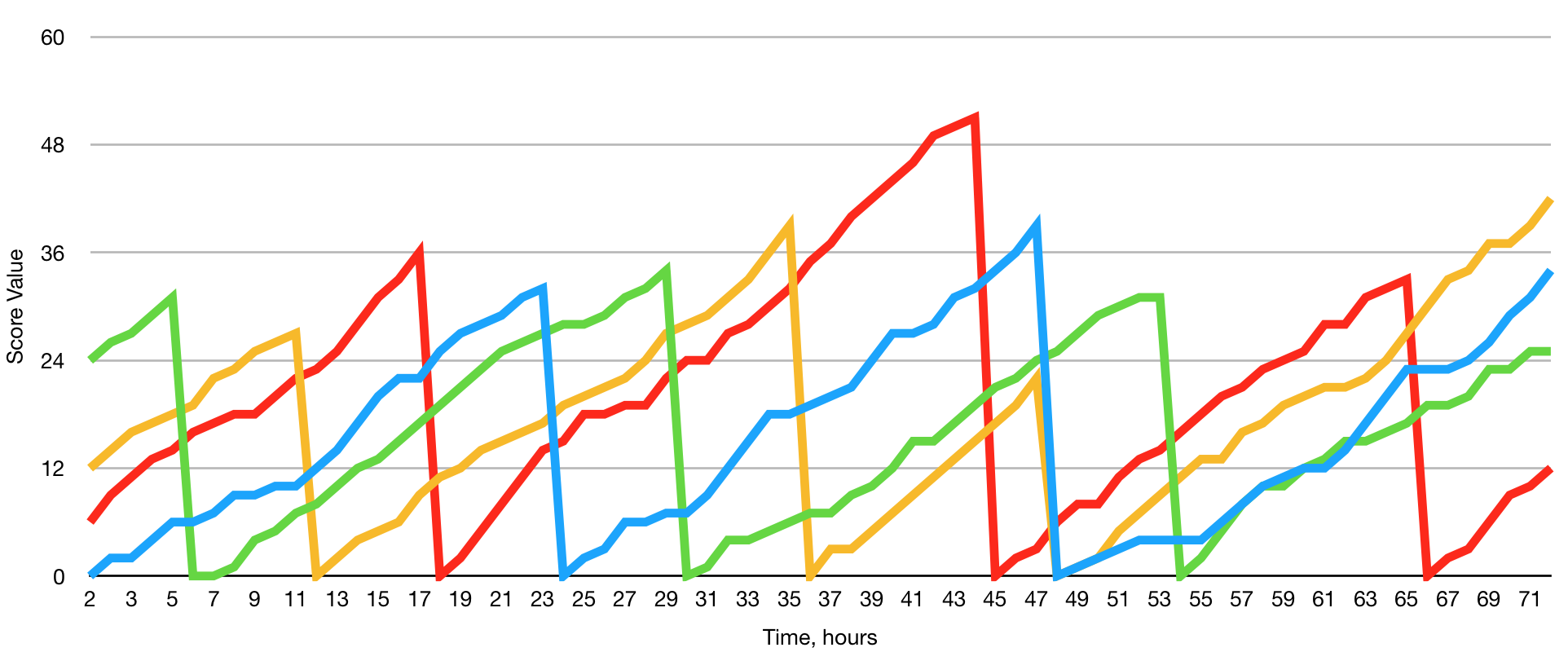
There is a “farm” inside each node, which is farming those scores and picks the largest one to use (the green line on the graph):
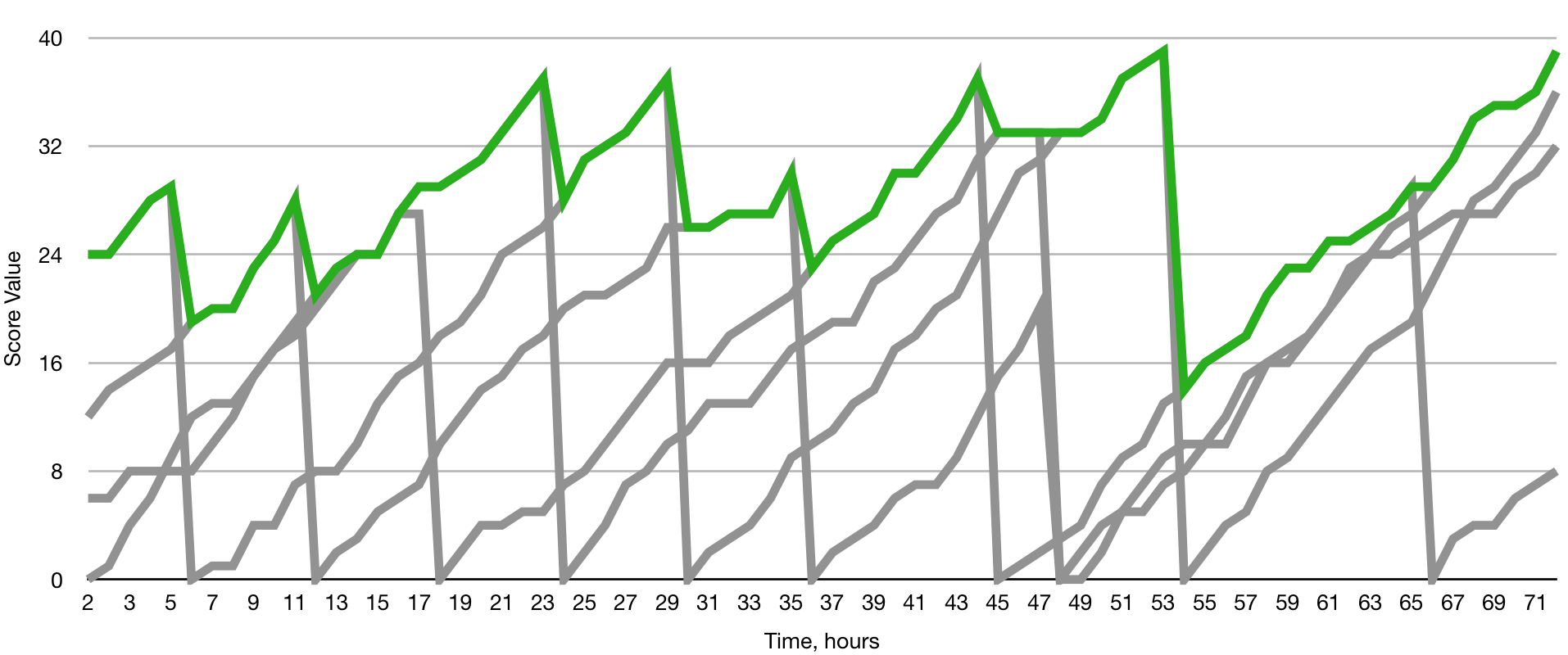
Obviously, the larger the number of threads, the more stable is the output. On the other hand, each thread is an additional CPU load.
The number of threads is configured via --threads command line argument.